Recently, a team led by Assistant Professor Zhang Qiang at the Zhejiang University–University of Illinois Urbana-Champaign Institute (ZJUI) reported a major advance in frontier scientific exploration empowered by large models. The study, carried out jointly by the College of Computer Science and Technology at Zhejiang University, ZJUI, and Tencent's Life Sciences Laboratory, was published in Nature Biotechnology. The paper introduces ERAST (Efficient Retrieval-Augmented Search Tool), a new platform for large-scale homology detection. Assistant Professor Zhang Qiang, Professor Chen Huajun from the College of Computer Science and Technology, Zhejiang University, and Chief Scientist Yao Jianhua from Tencent's Life Sciences Laboratory served as co–corresponding authors.

▲
Homology search is the foundational cornerstone of modern molecular biology, serving as the primary method for identifying biological sequences that share common evolutionary origins and functional similarity. It is indispensable for annotating newly discovered sequences and unraveling the fundamental mechanisms of molecular evolution. However, as global biological sequence databases have exploded to the billion-sequence scale, conventional tools including BLAST, Foldseek, and MMseqs2 face a fundamental trade-off between speed and accuracy, posing an increasingly severe bottleneck for large-scale life science research.
▲
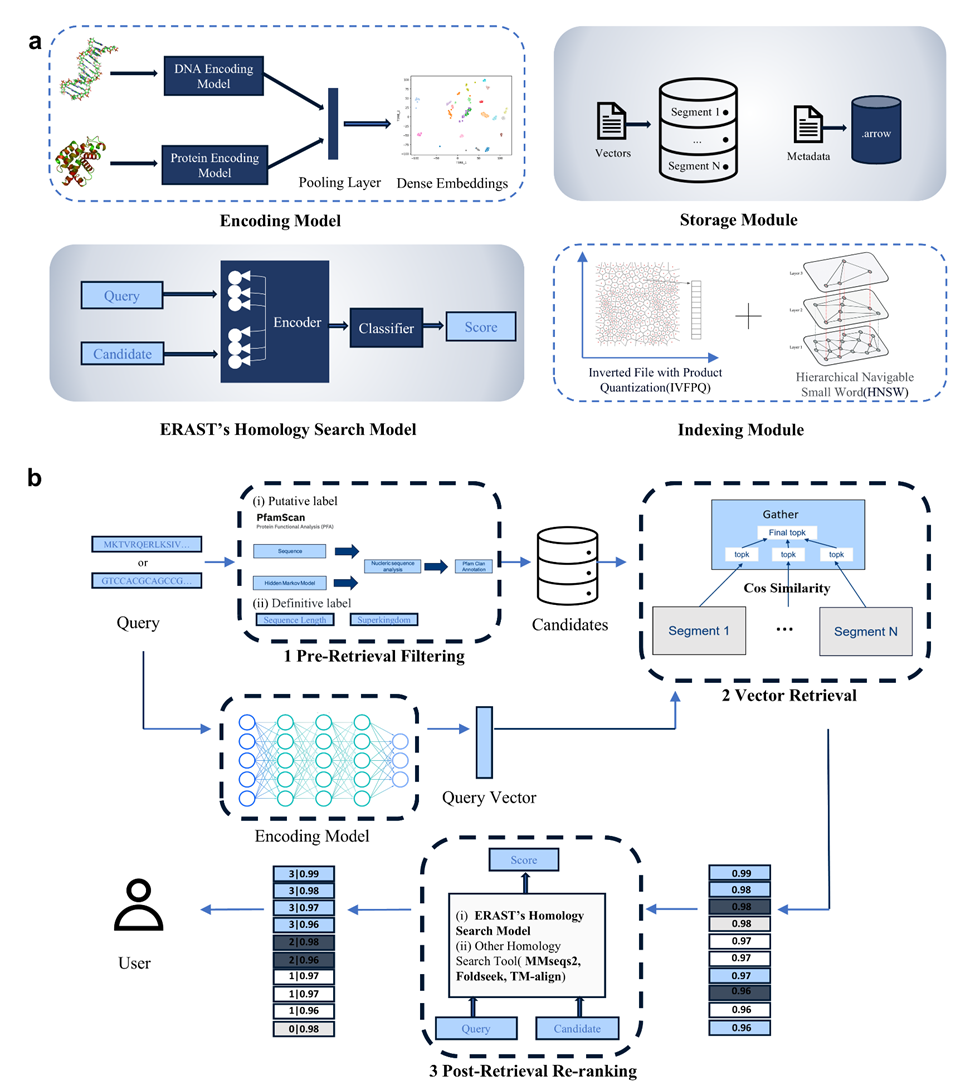
To overcome this critical limitation, the team developed ERAST (Efficient Retrieval-Augmented Search Tool), which innovatively integrates cutting-edge large language models with vector database technology within a modular retrieval-augmented architecture. Its three-stage synergistic pipeline, comprising pre-retrieval filtering, vector-based candidate retrieval, and post-retrieval reranking, delivers simultaneous improvements in efficiency and detection sensitivity. Uniquely, ERAST supports both protein and nucleotide sequences, including long nucleotide fragments exceeding 10,000 bp, a capability absent in most protein-only traditional tools.
As detailed in the Nature Biotechnology publication, ERAST powers the largest biological vector database reported to date, housing over 1 billion protein sequences and 30 million nucleotide sequences. Benchmarking on the SCOPe40 dataset demonstrates that ERAST outperforms state-of-the-art methods in both accuracy and efficiency, achieving a ~50× speedup over Foldseek and a remarkable 50,000× speedup over TM-align. This enables accurate homology searches across the entire billion-scale database in milliseconds.
This breakthrough enables unprecedented global-scale sequence annotation and reveals deep evolutionary links between ~94% of previously uncharacterized "dark proteins" and known functional proteins. More broadly, ERAST represents a transformative computational tool for the life sciences, with far-reaching applications in drug discovery, disease diagnosis, genetic engineering, and synthetic biology. It empowers researchers to redirect their focus from computational bottlenecks to core scientific insights, accelerating breakthroughs across basic and applied biological research.





