近日,浙江大学伊利诺伊大学厄巴纳香槟校区联合学院(ZJUI)研究员、助理教授张强团队在大模型赋能下的前沿科学探索(LLM for Science)中取得重要突破,该研究由浙江大学计算机科学与技术学院、ZJUI和腾讯生命科学实验室共同完成,相关成果发表于Nature旗舰期刊《自然·生物技术》(Nature Biotechnology),由ZJUI张强、浙江大学计算机科学与技术学院求是特聘教授陈华钧和腾讯生命科学实验室首席科学家姚建华共同担任本文的通讯作者。

▲相关成果发表于Nature旗舰期刊《自然·生物技术》
在现代分子生物学研究中,同源搜索不仅是识别具有共同祖先、功能相似生物序列的核心基石,更是表征新发现序列、揭示生命进化规律的关键技术手段。然而,随着宏基因组学等领域的飞速发展,全球生物序列数据库规模已呈指数级增长至数十亿条量级;传统同源搜索工具(如 BLAST、Foldseek、MMseqs2)在面对海量数据时,普遍陷入搜索效率低下与高精度需高算力成本的两难困境,已成为制约生命科学研究效率提升的关键瓶颈。在此背景下,构建能够同时实现高速检索与精准检测的超大规模向量数据库,成为生物信息学领域亟待突破的前沿方向与核心需求。
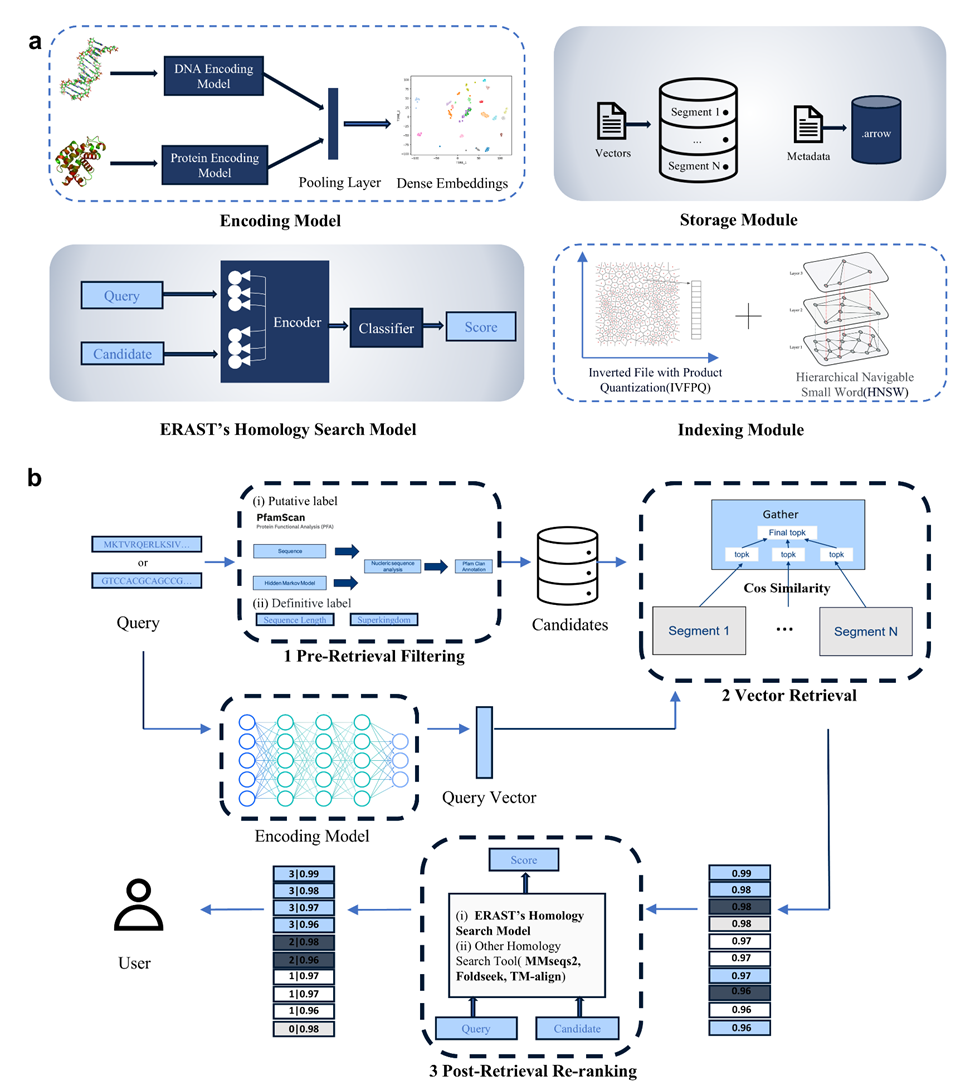
▲ERAST 系统架构及同源检索流程示意图
团队研发的ERAST(Efficient Retrieval-Augmented Search Tool)是一款专为超大规模生物序列检索与远程同源发现打造的高效同源检测工具,创新性融合前沿大语言模型与生物序列向量数据库技术,为生命科学研究提供了全新的技术解决方案。
ERAST 采用模块化检索增强的创新技术架构,将复杂的同源检索流程拆解为检索前过滤、向量检索、检索后重排序三个协同递进的阶段:先通过元数据精准筛选剔除无效序列,大幅减少冗余计算;再结合余弦距离度量与 IVFPQ、HNSW 索引算法实现候选序列的高效召回;最后依托自主研发的 EHSM 模型进行精细重排序,精准捕捉深层同源特征。同时,ERAST 通过分段存储与多线程并行策略进一步优化检索效率,全面兼容蛋白质与核酸两类序列,尤其支持长度超过 10000bp 的长核苷酸序列检索,应用场景显著优于多数仅支持蛋白质序列的传统工具。
依托上述技术创新,ERAST 在数据规模、检索性能与科学应用上均取得突破性进展:其一,已建成全球规模最大的生物序列向量数据库,收录超10亿条蛋白质序列与3000万条核酸序列,为十亿级规模的同源检索筑牢了数据基础;其二,在SCOPe40标准基准测试中,检索精度全面领先国际现有先进方法,计算效率更是实现量级式突破——相较Foldseek提速约50倍,相较TM-align提速高达50000倍,可在毫秒级完成十亿级数据库的精准同源检索;其三,研究团队依托ERAST对UniRef90 全量数据集完成全局聚类分析,成功揭示了约94%功能未知的 "暗蛋白" 与已知功能蛋白间的潜在进化关联,为蛋白质功能注释与未知蛋白机制研究提供了有力支撑,更为生命科学领域探索 "蛋白质暗物质" 开辟了新路径。
作为生物信息学领域的突破性工具,ERAST将为药物靶点发现、疾病分子诊断、基因编辑、合成生物学酶工程等前沿领域提供核心技术支撑,助力科研人员摆脱低效的计算等待,聚焦核心科学问题探索,全面加速生命科学研究的创新进程。





